本文共 2625 字,大约阅读时间需要 8 分钟。
在软件世界中,已经有大量所见即所得的HTML编辑器,绝大多数的编辑器都是用JavaScript及基于JavaScript的库构建而成。这些编辑器在处理各种与HTML相关的格式化以及生成HTML源数据时运转良好,但并不具备我们在商业报告中所需要的各种能力。例如,在一个具有典型的审阅/批准生命周期的发布中,创建图形、图表、跟踪变化以及插入注释是非常实用的。加之,Word天生就是离线工作的。创建新的文档或编辑现有文档时,无需网络连接。而浏览器/JavaScript的离线能力仍然有限。考虑到这些能力,有效利用为此目的专门开发的原生应用看起来是更好的解决方案。
\Apache (POI)是一个以加强版面向商业的报告和预览为目的,读取MS Word和MS Excel等Microsoft文档的杰出Java框架。它通过将Word文档转化为易读的HTML格式,提供了增强的数据读取能力。\\设计
\\POI库支持Office Open XML文件格式——OOXML(文字处理和电子表格的一种表示形式)。它包含了用于读取文档中各种区块的API。在将文档加载到POI内存中时,它会获取文档所有的元数据和内容。我们可以通过遍历文档中的各个区块(例如,段落、表格、单元格等。),很容易就读取到这些信息。不过,仅仅使用POI,我们还无法实现HTML等效元素的生成。
\例如,一段带有背景颜色的文本会被渲染为带有字体类型、背景颜色等格式化样式的HTML span元素。我们应该可以根据从POI中读取到的该文档区块的所有相关属性或样式,用Simple API for XML (SAX) API创建HTML元素。为了实现读取低级别文档区块的功能,应该有一个访问者模式风格的API顺序地读取文档中各个区块的内容和属性(格式化风格等)。\Xdocreport是在POI内核和POI-OOXML基础上用通用的OOXML-SCHEMA构建而成。它会在POI内核的帮助下加载文档,然后在poi-ooxml和ooxml-schemas的帮助下读取内容和元数据。由于使用了模式库,Xdocreport可以很方便地浏览文档中的元素。Xdocreport提供了访问者风格的API用于读取文档中的每个区块并以HTML格式生成内容。通过扩展该库,就可以处理各种格式的HTML样式并且克服对表结构和编号渲染的限制。下面的代码片段展示了如何使用所见即所得的方法完成这项工作。\\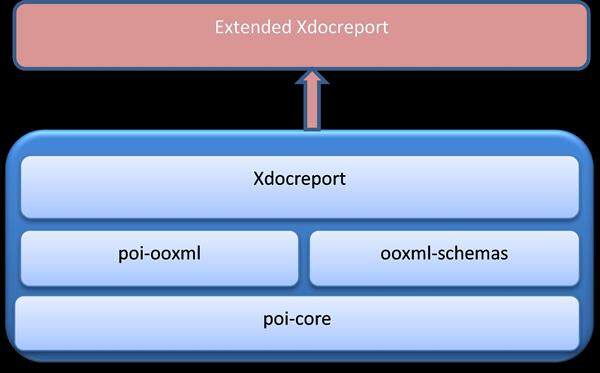
关于如何使用扩展的xdocreport控制HTML渲染,请参考下方的体系架构图
\\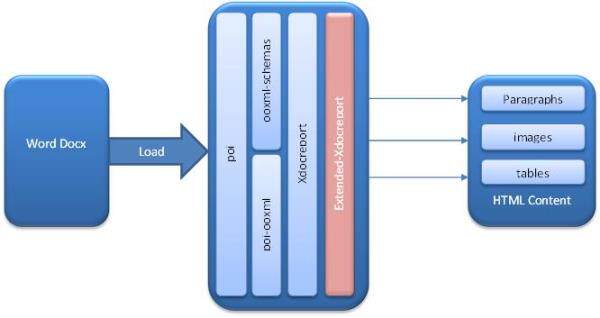
现在,我们开始尝试将包含各种组件的扩展docx文档,例如段落、表格、编号以及图片等,转换为HTML格式。
\\Docx到HTML转换的实现
\\加载docx文件流用于创建XWPFDocument对象
\\\FileInputStream fstream = new FileInputStream(\"Example.docx\");\XWPFDocument document = new XWPFDocument (fstream);\\//创建选项。这些选项用于控制图片的渲染等,\XHTMLOptions options = XHTMLOptions.create();\\// 创建输出流用于存储生成的HTML源文件\ByteArrayOutputStream out = new ByteArrayOutputStream();\IContentHandlerFactory factory = DefaultContentHandlerFactory.INSTANCE;\options.setIgnoreStylesIfUnused(false);\XHTMLMapper mapper = new XHTMLMapper (document, factory.create(out, null, options), options);\mapper.start();\out.close();\\\
我们可以将输出流转化成String对象并创建HTML文件。
\\\String html = new String(out.toByteArray(), “UTF-8”);\\\
我们可以很容易地将生成的HTML源数据附在servlet响应输出流当中。
\\自定义格式化样式和组件
\\我们可以扩展xdocreport中的XHTMLMapper类自定义从MS Word转化而来的默认的组件样式。我们还可以自定义HTML组件的渲染行为。
\例如,上标/下标是作为附加在span元素上的CSS样式生成的。但是,如果某个较早版本的浏览器无法理解这些CSS样式,而只能理解sup和sub标签该怎么办?所以,作为渲染的一部分,会强制生成sup/sub HTML标签,而不是CSS样式。下面的例子展示了如何重写visitRun方法以生成sup/sub HTML标签:\\\@Override\protected void visitRun(XWPFRun run, boolean pageNumber, String url, Object paragraphContainer) throws Exception {\ boolean isSuper = false;\ boolean isSub = false;\if (rPr.getVertAlign() != null) {\ int align = rPr.getVertAlign().getVal().intValue();\ if (STVerticalAlignRun.INT_SUPERSCRIPT == align) {\ isSuper = true;\ } else if (STVerticalAlignRun.INT_SUBSCRIPT == align) {\ isSub = true;\ }\ }\ .\.\.\if (isSuper || isSub) {\ startElement(isSuper ? \"SUP\" : \"SUB\ 转载地址:http://wcibm.baihongyu.com/